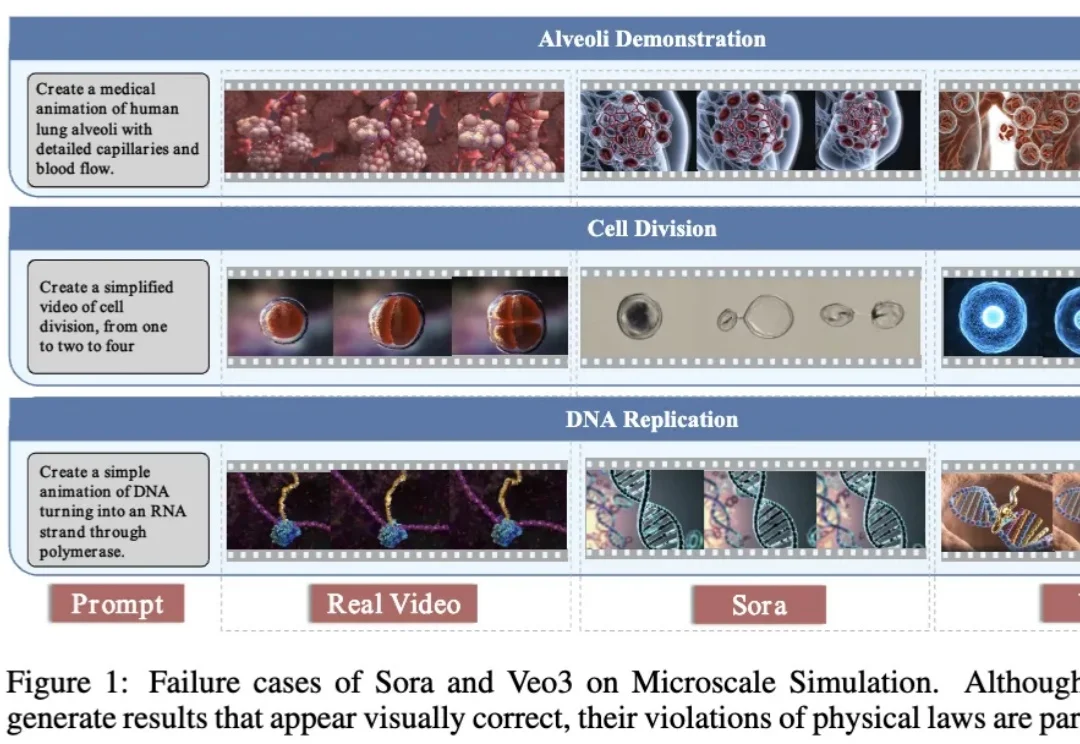
ICLR 2026|首个微观世界模型MicroVerse来了,AI开始模拟看不见的世界
ICLR 2026|首个微观世界模型MicroVerse来了,AI开始模拟看不见的世界过去两年,世界模型(World Model)正在成为大模型演进的重要方向。
来自主题: AI技术研报
9797 点击 2026-03-19 15:17
 搜索
搜索
过去两年,世界模型(World Model)正在成为大模型演进的重要方向。
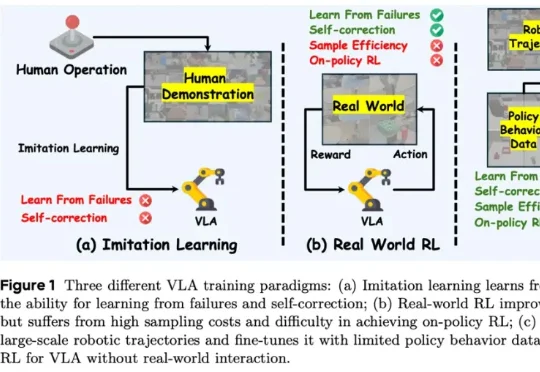
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。
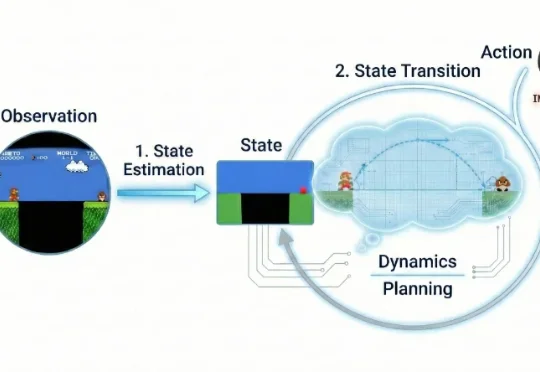
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
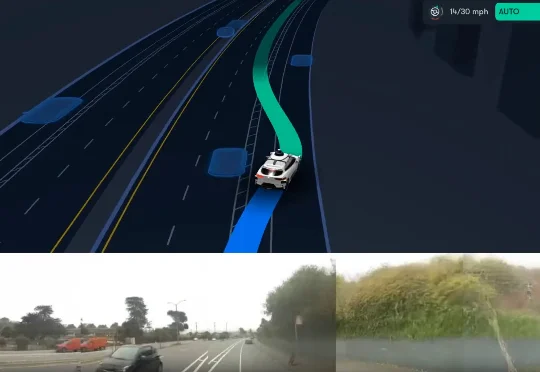
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。
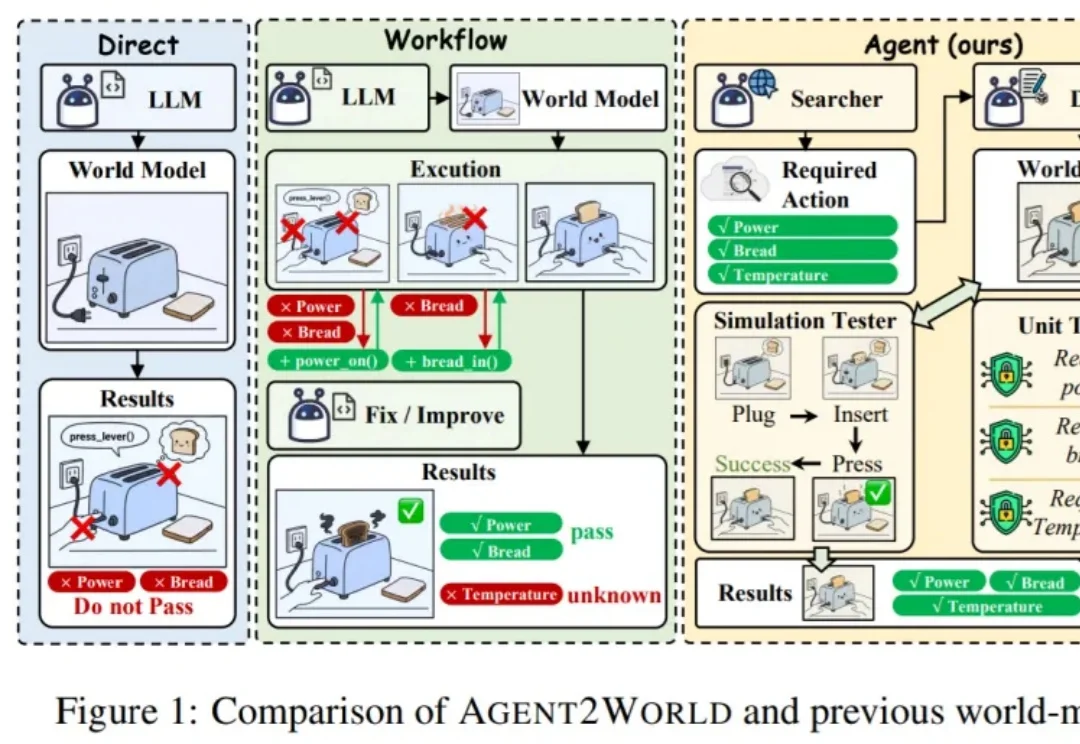
让模型真正 “能行动”,往往需要一个可执行、可验证的符号世界模型(Symbolic World Model):它不是抽象的文字描述,而是能被规划器或执行器直接调用的形式化定义 —— 例如 PDDL 领域 / 问题,或可运行的环境代码 / 模拟器。

还记得那个穿着「Lululemon」紧身衣、主打温柔陪伴的家用人形机器人 NEO 吗?

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。
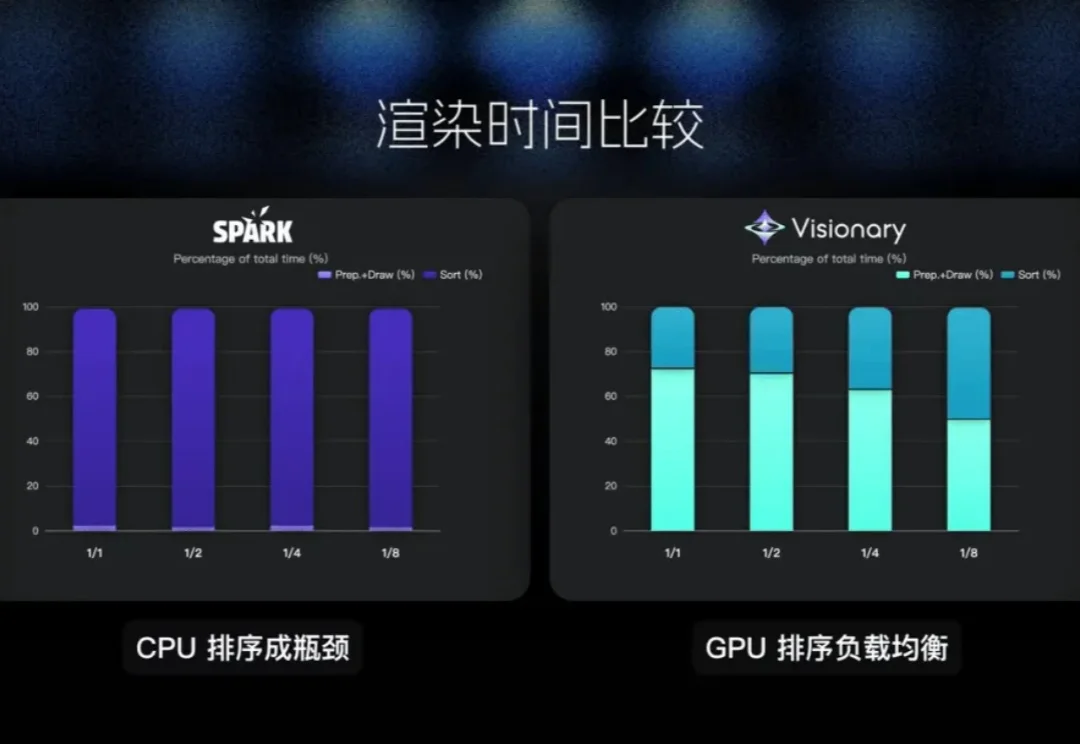
在李飞飞团队 WorldLabs 推出 Marble、引爆「世界模型(World Model)」热潮之后,一个现实问题逐渐浮出水面:世界模型的可视化与交互,依然严重受限于底层 Web 端渲染能力。

主攻 AI 视频与多媒体生成技术的独角兽 Runway 也来了一波大的:一口气来了 5 个「激动人心的宣布」。这一波更新之猛,甚至让人觉得他们是不是把过去半年的大招一次性全放了出来。Runway 这一波发布,不仅刷新了视频生成的各项指标,更重要的是,他们正式对外展示了其在通用世界模型(General World Models/GWM)上的野心。
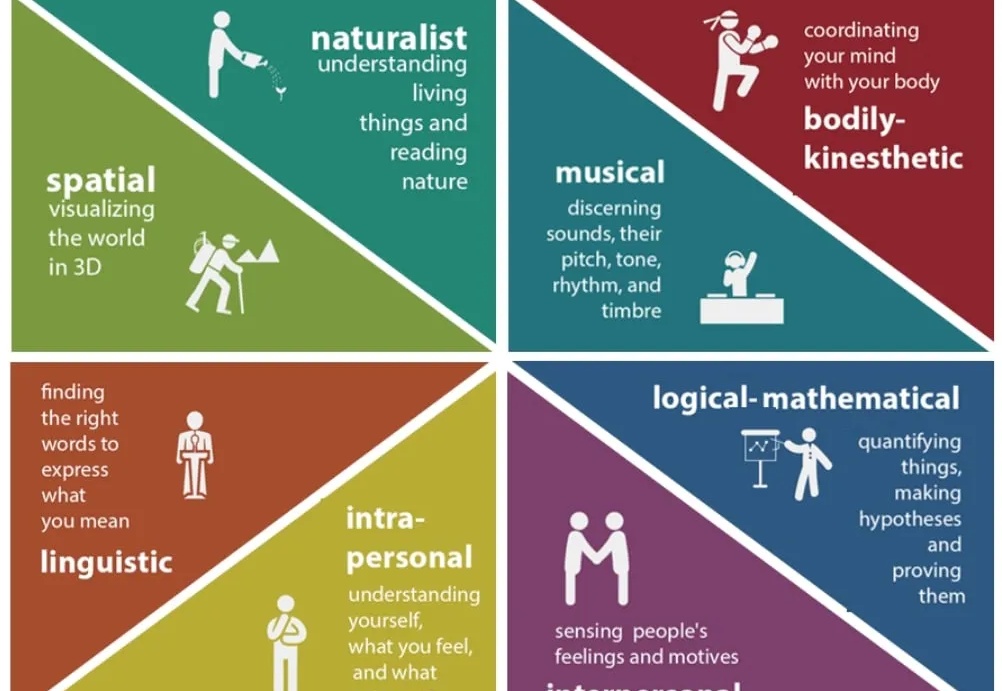
如今 LLM 的语言理解与生成能力已展现出惊人的广泛适用性,但随着 LLM 的发展,一个事实越发凸显:仅靠语言,仍不足以支撑真正的智能。